Build Modern Scientific Data Solutions
Operend empowers data managers and scientists to efficiently find, protect, and capitalize on their data assets—across clouds and on-premises.
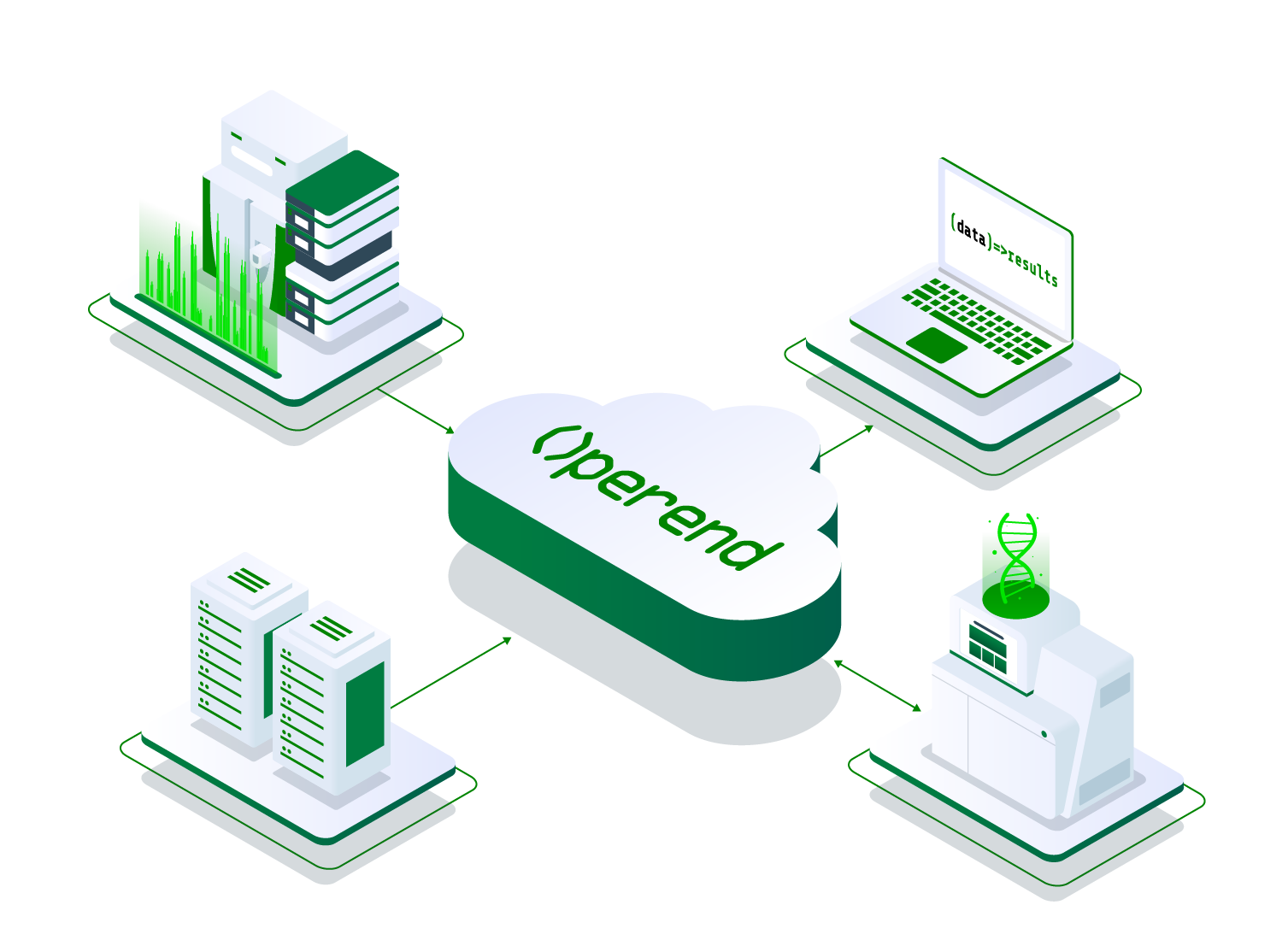
Operend empowers data managers and scientists to efficiently find, protect, and capitalize on their data assets—across clouds and on-premises.
Quickly locate files and datasets in a sea of scientific data with powerful metadata and search tools.
Operate on files where and how you need them, with seamless, secure access across environments.
Unify instruments, file systems, clouds, and users with robust management and automation.
Connect to data lakes, warehouses, and analytics tools for end-to-end scientific workflows.
Research spans clouds and on-premises. Operend simplifies data flow management, reducing complexity and time-to-insight.
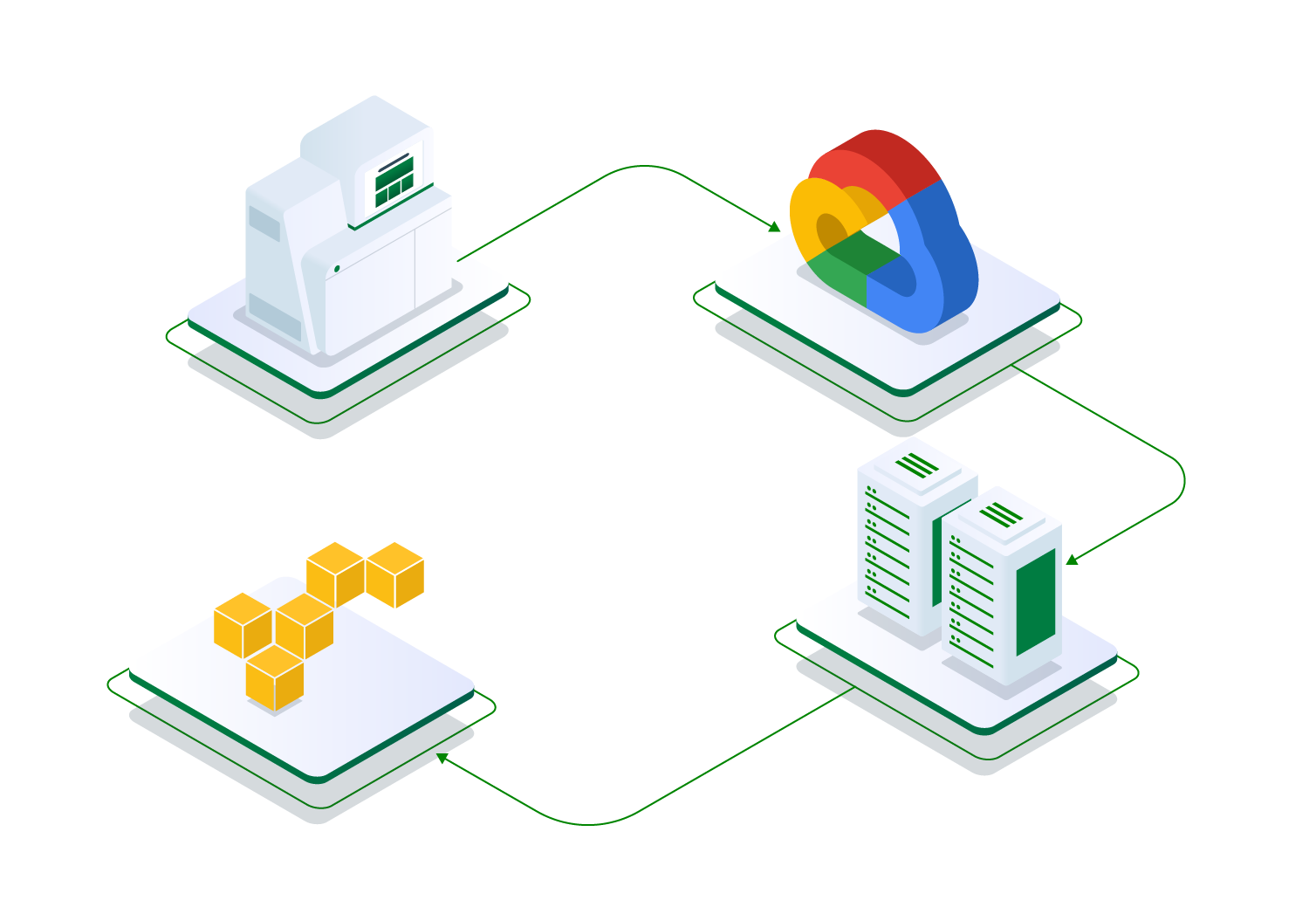

Go beyond file storage: query, analyze, and integrate with data lakes and warehouses. Operend is your bridge to modern data science.
Have questions or want a demo? Reach out and our team will get back to you.